Table 3.1. Standard Character Sets and Encodings
| XML Name | Java Name | First supported in Java | Scripts and Languages |
|---|---|---|---|
| ISO-8859-1 | 8859_1 | 1.1 | Latin-1: ASCII plus the accented characters needed for most Western European languages including Albanian, Basque, Breton, Catalan, Cornish, Danish, Dutch, English, Estonian, Faroese, Finnish, French, Frisian, Galician, German, Greenlandic, Icelandic, Irish, Italian, Latin, Luxemburgish, Norwegian, Portuguese, Rhaeto-Romanic, Scottish Gaelic, Sorbian, Spanish, and Swedish as well as many non-European languages written in the Latin alphabet such as Swahili and Malaysian |
| ISO-8859-2 | 8859_2 | 1.1 | Latin-2: ASCII plus the accented characters needed for most Central European languages including Albanian, Croatian, Czech, Finnish, German, Hungarian, Latin, Polish, Romanian, Slovak, Slovenian, and Sorbian |
| ISO-8859-3 | 8859_3 | 1.1 | Latin-3: ASCII plus the accented characters needed for most Southern European languages including English, Esperanto, Finnish, French, German, Italian, Latin, Maltese, Portuguese, and Turkish |
| ISO-8859-4 | 8859_4 | 1.1 | Latin-4: ASCII plus the accented characters needed for most Northern European languages including Danish, English, Estonian, Finnish, German, Greenlandic, Latin, Latvian, Lithuanian, Norwegian, S�mi, Slovenian, and Swedish |
| ISO-8859-5 | 8859_5 | 1.1 | ASCII plus Cyrillic |
| ISO-8859-6 | 8859_6 | 1.1 | ASCII plus Arabic |
| ISO-8859-7 | 8859_7 | 1.1 | ASCII plus Greek |
| ISO-8859-8 | 8859_8 | 1.1 | ASCII plus Hebrew |
| ISO-8859-9 | 8859_9 | 1.1 | Latin-5: same as Latin-1 except the Turkish letters Ğ, ğ, İ, ı, Ş, and ş take the place of the Icelandic letters þ, Þ, ý, Ý, Ð, and ð |
| ISO-8859-13 | ISO8859_13 | 1.3 | Latin-7: ASCII plus the accented characters needed for most Baltic languages including Latvian, Lithuanian, Estonian, and Finnish, as well as English, Danish, Swedish, German, Slovenian, and Norwegian. |
| ISO-8859-15 | ISO8859_15_FDIS | 1.2 | Latin-9: same as Latin-1 but with the Euro sign € instead of the international currency symbol ¤. It also replaces the infrequently used symbol characters ¦, ¨, ´, ¸, ¼, ½, and ¾ with the infrequently used French and Finnish letters Š, š, Ž, ž, Œ, œ, and Ÿ. |
| UTF-8 | UTF8 | 1.1 | The default encoding of XML documents; each Unicode character is represented in between 1 and 4 bytes. |
| UTF-16 | UnicodeBig or UnicodeLittle | 1.2 | An encoding of Unicode in which characters in the Basic Multilingual Plane are encoded in two bytes, and all other characters are encoded as two two-byte surrogates |
| ISO-10646-UCS-2 | N/A | N/A | A straightforward encoding in which each Unicode character is represented as a two-byte integer; cannot represent characters outside the Basic Multilingual Plane |
| ISO-10646-UCS-4 | N/A | N/A | A straightforward encoding in which each Unicode character is represented as a four-byte integer |
| ISO-2022-JP | JIS | 1.1 | Japanese |
| Shift_JIS | SJIS | 1.1 | Japanese |
| EUC-JP | EUCJIS | 1.1 | Japanese |
| US-ASCII | ASCII | 1.2 | English |
| GBK | GBK | 1.1 | Simplified Chinese |
| Big5 | Big5 | 1.1 | Traditional Chinese |
| ISO-2022-CN | ISO2022CN | 1.1 | Traditional Chinese |
| ISO-2022-KR | ISO2022KR | 1.1 | Korean |
The author has deliberately omitted XML legal encodings that are not yet supported by Java such as ISO-8859-10, ISO-8859-11, ISO-8859-14, and ISO-8859-16. It’s not hard to add them in Java 1.4; but since they’re not available by default, you’re better off picking UTF-8 or one of the other encodings of Unicode.
package ch4_package;
import java.io.*;
//import java.util.Scanner;
import java.math.BigInteger;
public class Test_This {
public static void main(String[] args) throws IOException
{
// TODO Auto-generated method stub
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String file_name ="";
Process pp = new Process();
try{
//System.out.println("---While Loop---");
//writing xml to a file write_xml.xml
System.out.print("Please Enter a xml File name: ");
file_name = br.readLine();
//System.out.print("Now the text to be added : ");
//str_text = br.readLine();
pp.read_file(file_name);
}//try
catch(NumberFormatException e)
{ System.out.println("data was blank");}
}
}
class Process {
public void read_file(String str)throws IOException
{
//FileReader s = null;
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
try {
OutputStream os_file_fos= new FileOutputStream(str);
OutputStream os_Buff_fos= new BufferedOutputStream(os_file_fos);
OutputStreamWriter out = new OutputStreamWriter(os_Buff_fos, "8859_1");
System.out.println("satrted writing in xml");
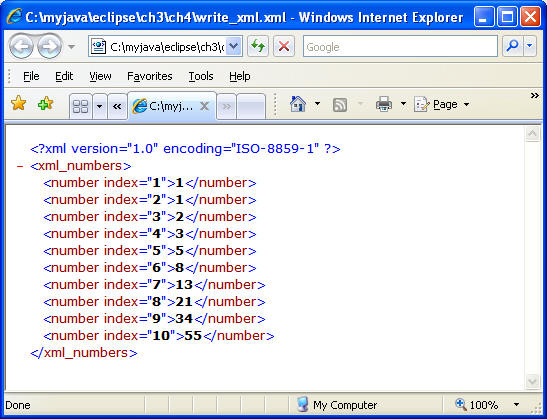
out.write("<?xml version=\"1.0\" ");
out.write("encoding=\"ISO-8859-1\"?>\r\n");
out.write("<xml_numbers>\r\n");
for (int i = 1; i <= 10; i++) {
out.write(" <number index=\"" + i + "\">");
out.write(low.toString());
out.write("</number>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</xml_numbers>\r\n");
out.flush(); // Don't forget to flush!
out.close();
}
catch (UnsupportedEncodingException e) {
System.out.println(
"This VM does not support the Latin-1 character set."
);
}
catch (IOException e) {
System.out.println(e.getMessage());
}
System.out.println("completed writing in xml");
}
}